The Gulf pushes for AI independence
20 May 2025
Published online 20 May 2025
Researchers across Africa, Asia and the Middle East are building their own language models designed for local tongues, cultural nuance and digital independence

Abstract network and data stream - stock photo
In a high-stakes artificial intelligence race between the United States and China, an equally transformative movement is taking shape elsewhere. From Cape Town to Bangalore, from Cairo to Riyadh, researchers, engineers and public institutions are building homegrown AI systems, models that speak not just in local languages, but with regional insight and cultural depth.
The dominant narrative in AI, particularly since the early 2020s, has focused on a handful of US-based companies like OpenAI with GPT, Google with Gemini, Meta’s LLaMa, Anthropic’s Claude. They vie to build ever larger and more capable models. Earlier in 2025, China’s DeepSeek, a Hangzhou-based startup, added a new twist by releasing large language models (LLMs) that rival their American counterparts, with a smaller computational demand. But increasingly, researchers across the Global South are challenging the notion that technological leadership in AI is the exclusive domain of these two superpowers.
Instead, scientists and institutions in countries like India, South Africa, UAE and Saudi Arabia are rethinking the very premise of generative AI. Their focus is not on scaling up, but on scaling right, building models that work for local users, in their languages, and within their social and economic realities.
“How do we make sure that the entire planet benefits from AI?” asks Benjamin Rosman, a professor at the University of the Witwatersrand and a lead developer of InkubaLM, a generative model trained on five African languages. “I want more and more voices to be in the conversation”.
Beyond English, beyond Silicon Valley
Large language models work by training on massive troves of online text. While the latest versions of GPT, Gemini or LLaMa boast multilingual capabilities, the overwhelming presence of English-language material and Western cultural contexts in these datasets skews their outputs. For speakers of Hindi, Arabic, Swahili, Xhosa and countless other languages, that means AI systems may not only stumble over grammar and syntax, they can also miss the point entirely.
“In Indian languages, large models trained on English data just don’t perform well,” says Janki Nawale, a linguist at AI4Bharat, a lab at the Indian Institute of Technology Madras. “There are cultural nuances, dialectal variations, and even non-standard scripts that make translation and understanding difficult.” Nawale’s team builds supervised datasets and evaluation benchmarks for what specialists call “low resource” languages, those that lack robust digital corpora for machine learning.
It’s not just a question of grammar or vocabulary. “The meaning often lies in the implication,” says Vukosi Marivate, a professor of computer science at the University of Pretoria, in South Africa. “In isiXhosa, the words are one thing but what’s being implied is what really matters.” Marivate co-leads Masakhane NLP, a pan-African collective of AI researchers that recently developed AFROBENCH, a rigorous benchmark for evaluating how well large language models perform on 64 African languages across 15 tasks. The results, published in a preprint in March, revealed major gaps in performance between English and nearly all African languages, especially with open-source models.
Similar concerns arise in the Arabic-speaking world. “If English dominates the training process, the answers will be filtered through a Western lens rather than an Arab one,” says Mekki Habib, a robotics professor at the American University in Cairo. A 2024 preprint from the Tunisian AI firm Clusterlab finds that many multilingual models fail to capture Arabic’s syntactic complexity or cultural frames of reference, particularly in dialect-rich contexts.
Governments step in
For many countries in the Global South, the stakes are geopolitical as well as linguistic. Dependence on Western or Chinese AI infrastructure could mean diminished sovereignty over information, technology, and even national narratives. In response, governments are pouring resources into creating their own models.
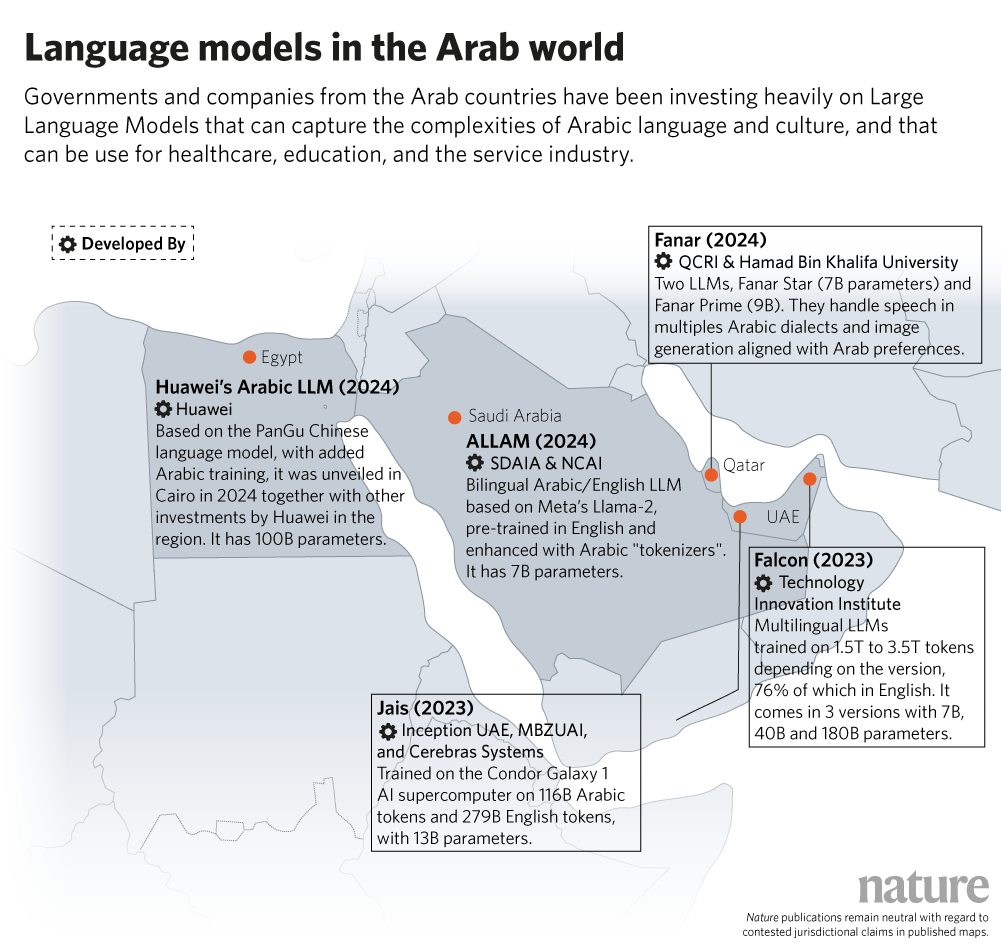
Saudi Arabia’s national AI authority, SDAIA, has built ‘ALLaM,’ an Arabic-first model based on Meta’s LLaMa-2, enriched with more than 540 billion Arabic tokens. The United Arab Emirates has backed several initiatives, including ‘Jais,’ an open-source Arabic-English model built by MBZUAI in collaboration with US chipmaker Cerebras Systems and the Abu Dhabi firm Inception. Another UAE-backed project, Noor, focuses on educational and Islamic applications.
In Qatar, researchers at Hamad Bin Khalifa University, and the Qatar Computing Research Institute, have developed the Fanar platform and its LLMs Fanar Star and Fanar Prime. Trained on a trillion tokens of Arabic, English, and code, Fanar’s tokenization approach is specifically engineered to reflect Arabic’s rich morphology and syntax.
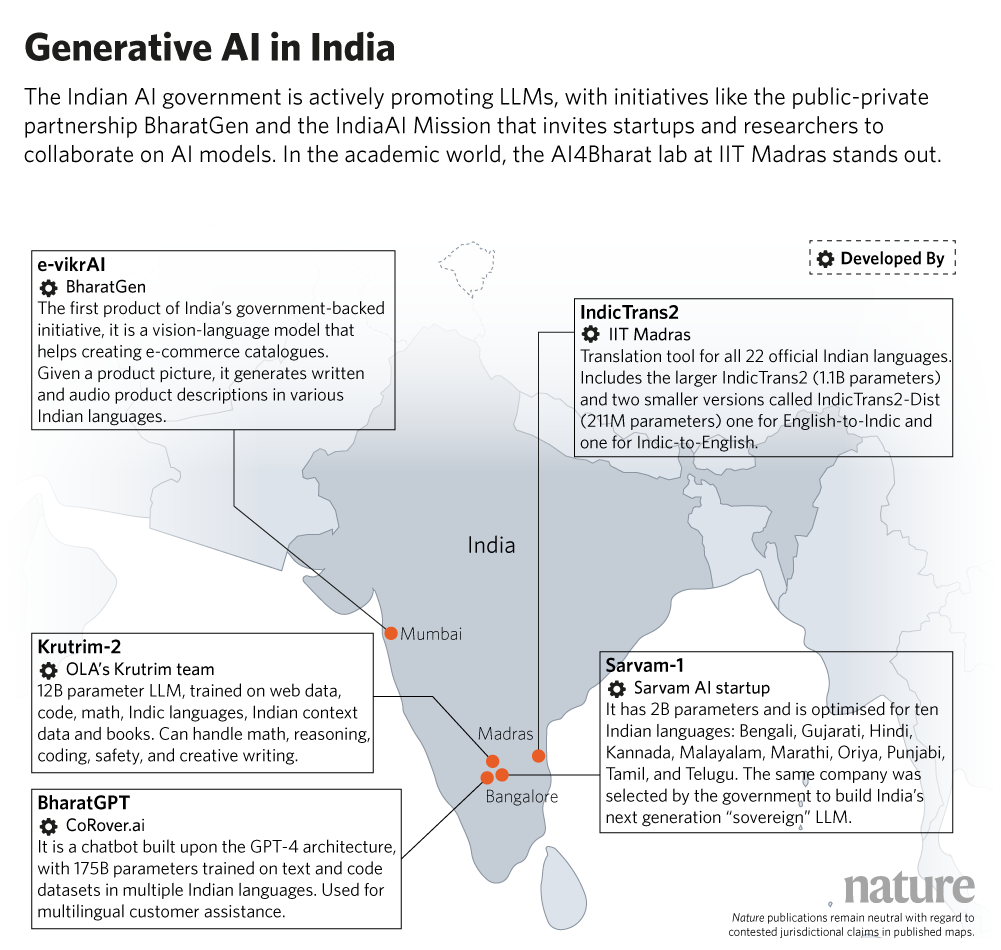
India has emerged as a major hub for AI localization. In 2024, the government launched BharatGen, a public-private initiative funded with 235 crore (€26 million) initiative aimed at building foundation models attuned to India’s vast linguistic and cultural diversity. The project is led by the Indian Institute of Technology in Bombay and also involves its sister organizations in Hyderabad, Mandi, Kanpur, Indore, and Madras. The programme’s first product, e-vikrAI, can generate product descriptions and pricing suggestions from images in various Indic languages. Startups like Ola-backed Krutrim and CoRover’s BharatGPT have jumped in, while Google’s Indian lab unveiled MuRIL, a language model trained exclusively on Indian languages. The Indian governments’ AI Mission has received more than180 proposals from local researchers and startups to build national-scale AI infrastructure and large language models, and the Bengaluru-based company, AI Sarvam, has been selected to build India’s first ‘sovereign’ LLM, expected to be fluent in various Indian languages.
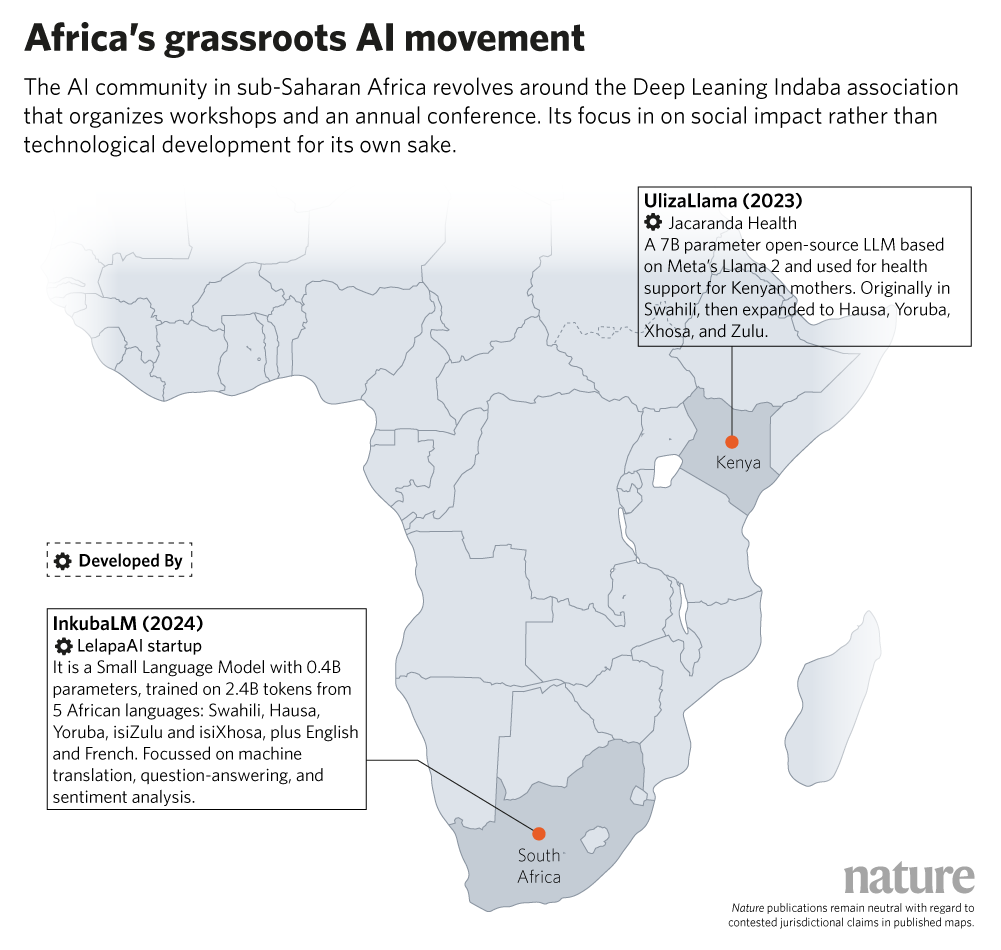
In Africa, much of the energy comes from the ground up. Masakhane NLP and Deep Learning Indaba, a pan-African academic movement, have created a decentralized research culture across the continent. One notable offshoot, Johannesburg-based Lelapa AI, launched InkubaLM in September 2024. It’s a ‘small language model’ (SLM) focused on five African languages with broad reach: Swahili, Hausa, Yoruba, isiZulu and isiXhosa.
“With only 0.4 billion parameters, it performs comparably to much larger models,” says Rosman. The model’s compact size and efficiency are designed to meet Africa’s infrastructure constraints while serving real-world applications. Another African model is UlizaLlama, a 7-billion parameter model developed by the Kenyan foundation Jacaranda Health, to support new and expectant mothers with AI-driven support in Swahili, Hausa, Yoruba, Xhosa, and Zulu.
India’s research scene is similarly vibrant. The AI4Bharat laboratory at IIT Madras has just released IndicTrans2, that supports translation across all 22 scheduled Indian languages. Sarvam AI, another startup, released its first LLM last year to support 10 major Indian languages. And KissanAI, co-founded by Pratik Desai, develops generative AI tools to deliver agricultural advice to farmers in their native languages.
The data dilemma
Yet building LLMs for underrepresented languages poses enormous challenges. Chief among them is data scarcity. “Even Hindi datasets are tiny compared to English,” says Tapas Kumar Mishra, a professor at the National Institute of Technology, Rourkela in eastern India. “So, training models from scratch is unlikely to match English-based models in performance.”
Rosman agrees. “The big-data paradigm doesn’t work for African languages. We simply don’t have the volume.” His team is pioneering alternative approaches like the Esethu Framework, a protocol for ethically collecting speech datasets from native speakers and redistributing revenue back to further development of AI tools for under-resourced languages. The project’s pilot used read speech from isiXhosa speakers, complete with metadata, to build voice-based applications.
In Arab nations, similar work is underway. Clusterlab’s 101 Billion Arabic Words Dataset is the largest of its kind, meticulously extracted and cleaned from the web to support Arabic-first model training.
The cost of staying local
But for all the innovation, practical obstacles remain. “The return on investment is low,” says KissanAI’s Desai. “The market for regional language models is big, but those with purchasing power still work in English.” And while Western tech companies attract the best minds globally, including many Indian and African scientists, researchers at home often face limited funding, patchy computing infrastructure, and unclear legal frameworks around data and privacy.
“There’s still a lack of sustainable funding, a shortage of specialists, and insufficient integration with educational or public systems,” warns Habib, the Cairo-based professor. “All of this has to change.”
A different vision for AI
Despite the hurdles, what’s emerging is a distinct vision for AI in the Global South – one that favours practical impact over prestige, and community ownership over corporate secrecy.
“There’s more emphasis here on solving real problems for real people,” says Nawale of AI4Bharat. Rather than chasing benchmark scores, researchers are aiming for relevance: tools for farmers, students, and small business owners.
And openness matters. “Some companies claim to be open-source, but they only release the model weights, not the data,” Marivate says. “With InkubaLM, we release both. We want others to build on what we’ve done, to do it better.”
In a global contest often measured in teraflops and tokens, these efforts may seem modest. But for the billions who speak the world’s less-resourced languages, they represent a future in which AI doesn’t just speak to them, but with them.
doi:10.1038/nmiddleeast.2025.65
20 May 2025
20 May 2025
08 May 2025
Sign-up to receive our e-alert update every two weeks to keep up with everything new on the portal.
Sign up for e-alerts
Stay connected: