هل تُحقّق دول الخليج الاستقلالية في مجال الذكاء الاصطناعي؟
20 May 2025
نشرت بتاريخ 20 مايو 2025
شرع باحثون على امتداد إفريقيا وآسيا والشرق الأوسط في تصميم نماذج ذكاء اصطناعي تراعي اللغات المحلية والاختلافات الثقافية، على الطريق إلى تحقيق الاستقلال الرقمي.

حقوق الصورة: Yuichiro Chino/ Moment/ Getty Images
في خضم سباق عالي المخاطر للتسلُح بأدوات الذكاء الاصطناعي بين الولايات المتحدة والصين، أخذت شرارة ثورة مماثلة تتبلور في بقاع أخرى. فمن كيب تاون إلى بنغالور، ومن القاهرة إلى الرياض، عكف باحثون ومهندسون ومؤسسات عامة على تصميم أنظمة ذكاء اصطناعي منتجة محليًا، لا تتحدث فحسب لغات تلك المناطق، بل تتبنى رؤاها الإقليمية وأبعادها الثقافية.
ركزت السردية السائدة في مجال أنظمة الذكاء الاصطناعي منذ أوائل هذا العقد على عدد من الشركات الأمريكية المنتجة لهذه الأنظمة مثل شركة «أوبن إيه آي» Open AI ونظامها «جي بي تي» GPT، وشركة «جوجل» ونظامها «جيميناي» Gemini، وشركة «ميتا» Meta ونظامها «لاما» LLaMa، وشركة «أنثروبيك» Anthropic ونظامها «كلود» Claude. لكن في الوقت الذي تنافست فيه هذه الشركات لبناء أنظمة ذكاء اصطناعي أكبر وأقوى أداء، في أوائل عام 2025، سلكت هذه السردية منعطفًا جديدًا، مع إطلاق الشركة الصينية «ديب سيك» Deep Seek لنماذج لغوية كبيرة تنافس نظيرتها الأمريكية بقدر أقل من المتطلبات الحوسبية. واليوم، من كافة ربوع الجنوب العالمي، يتزايد عدد الباحثين الذين انبروا للتصدي لفكرة احتكار هاتين القوتين العظمتين للريادة التقنية في هذا الحقل.
فأخذ علماء ومؤسسات من دول مثل الهند وجنوب إفريقيا ومصر والسعودية في تبني منظور جديد يغير قواعد اللعبة في مجال الذكاء الاصطناعي التوليدي. لم ينصب اهتمام هذه الأطراف الجديدة على توسعة انتشار هذه النماذج، وإنما على تصميمها لتلبي احتياجات المستخدم المحلي بلغته، مع الأخذ في الاعتبار واقعه الاجتماعي والاقتصادي.
في هذا الإطار، يقول بينجامين روزمان، وهو أستاذ في جامعة فيتفاترسراند في مدينة جوهانسبرج بجنوب إفريقيا، وأحد كبار مطوري نموذج الذكاء الاصطناعي التوليدي «إنكوبال إم» InkubalM، المُدرب على خمس لغات إفريقية: "حرصًا على استفادة الكوكب بأسره من نماذج الذكاء الاصطناعي، أتمنى أن تتسع دائرة النقاش لتشمل أصواتًا متنوعة ومتزايدة".
ذكاء اصطناعي لا يولد في وادي السليكون!
تؤدي نماذج القوالب اللغوية الكبيرة مهامها بالتدرُب على فهم فيض شاسع من النصوص على الإنترنت. ومع أن الإصدارات الأحدث من نظام «جي بي تي»، أو «جيميناي»، أو «لاما» تتميز بإجادتها للغات متعددة، فالقدر الهائل الذي تنطوي عليه مجموعات البيانات التي تتدرب عليها هذه الأنظمة من السياقات الغربية أو المواد الصادرة باللغة الإنجليزية يضفي انحيازًا على مخرجاتها. ويعني هذا لمتحدثي الهندية والعربية والسواحيلية والخوسية وعدد لا حصر له من اللغات، أن أنظمة الذكاء الاصطناعي لن تقع فحسب في أخطاء في القواعد النحوية وفي بناء الجمل، بل قد تخطئ فهم مغزى النص تمامًا.
في ذلك الصدد، تقول جانكي ناوالي، وهي عالمة لغة في مختبر «إيه آي فور بْهارات» AI4Bharat التابع للمعهد الهندي للتكنولوجيا في مدراس (تشيناي): "في حال اللغات الهندية، لا تبلي نماذج القوالب اللغوية الكبيرة المُدربة على بيانات باللغة الإنجليزية بلاءً حسنًا. فبعض الفروق الثقافية الدقيقة، والاختلافات بين اللهجات، والنصوص العامية تضفي صعوبة على ترجمة هذه اللغات وفهمها". من هنا، يعمل فريق ناوالي على تصميم مجموعات بيانات والإشراف على تدرُب أنظمة الذكاء الاصطناعي عليها، ووضع معايير لتقييم أداء هذه الأنظمة في ما يسميه المتخصصون بـ"اللغات محدودة الموارد"، أي التي لا تتوفر لها مجموعات بيانات رقمية محكمة من أجل استخدامها في عمليات تعلُم الآلة.
غير أن المشكلة ليست قاصرة على قواعد النحو أو المفردات اللغوية. فحسبما يفيد فوكوسي ماريفاتي، وهو أستاذ علوم حاسوب في جامعة بريتوريا في جنوب إفريقيا: "كثيرًا ما يكمن المعنى بين السطور. على سبيل المثال، في اللغة الخوسية، تحمل الكلمات معاني محددة، لكن مدلولها الضمني هو ما يهم حقًا". يشارك ماريفاتي في قيادة اتحاد باسم «ماساكاني إن إل بي» Masakhane NLP، وهو اتحاد إفريقي يضم باحثين في مجال الذكاء الاصطناعي، نجح مؤخرًا في تطوير مجموعة معايير محكمة باسم «أفروبنش» AFROBENCH لتقييم إجادة النماذج اللغوية الكبيرة لـ64 لغة إفريقية في 15 مهمة. وأسفرت نتائج أبحاث الفريق، التي نُشرت في مسودة بحثية مارس الماضي، عن قصور جسيم في أداء هذه الأنظمة في جميع اللغات الإفريقية تقريبًا، مقارنة بالإنجليزية، لا سيما في حال النماذج مفتوحة المصدر.
ونجد المخاوف ذاتها إزاء كفاءة هذه الأنظمة في البلدان الناطقة بلغة الضاد. فيقول مكي حبيبي، أستاذ علم الروبوتات في الجامعة الأمريكية في القاهرة: "إذا هيمنت الإنجليزية على عملية تدريب الذكاء الاصطناعي، ستخضع أجوبته لفلترة تعتمد عدسة المنظور الغربي لا العربي". وقد خلصت مسودة بحثية نشرتها شركة الذكاء الاصطناعي التونسية «كلاسترلاب» Clusterlab في عام 2024 إلى أن نماذج الذكاء الاصطناعي متعددة اللغات تفشل في التعبير عن ما يرتبط بلغة الضاد من تراكيب لغوية ثرية وأطر ثقافية، لا سيما في السياقات التي تزخر باللهجات.
الحكومات: طرف جديد في المعادلة
يخوض العديد من دول الجنوب العالمي هذا الرهان لاعتبارات جيوسياسية، وليس لغوية فقط. فالاعتماد على البِنى التحتية الغربية أو الصينية في مجال الذكاء الاصطناعي من شأنه إضعاف السيادة المعلوماتية والتقنية وتقويض السيطرة على السرديات الوطنية. لذا، أخذت بعض حكومات دول الجنوب العالمي في تكريس جانب من طاقاتها لإنتاج نماذج ذكاء اصطناعي خاصة بها.
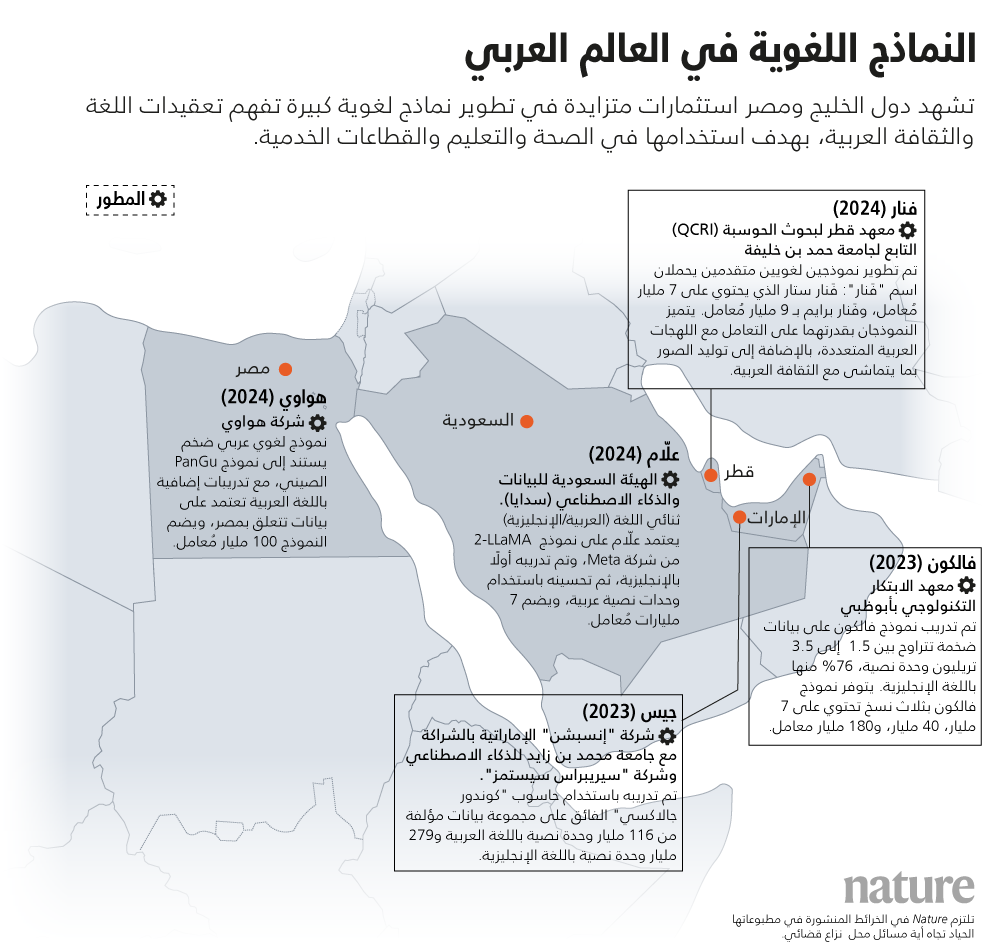
على سبيل المثال، صممت الهيئة السعودية للبيانات والذكاء الاصطناعي (سدايا) نموذج «علّام» ALLaM، الموجّه بالدرجة الأولى للعالم العربي، وهو يرتكز على نموذج «لاما-2» لشركة «ميتا». وقد أثري بما يزيد على 540 مليار وحدة بيانات نصية عربية يشار إليها باسم التوكن. كذلك دعًّمت الإمارات العربية المتحدة عدة مبادرات مماثلة، منها مبادرة «جيس» Jais، وهو نموذج ذكاء اصطناعي مفتوح المصدر يتحدث العربية والإنجليزية، صممته جامعة محمد بن زايد للذكاء الاصطناعي بالتعاون مع شركة تصنيع الرقاقات الحوسبية «سيريبراس سيستمز» Cerebras Systems، وشركة «إنسبشن» Inception الكائنة في مدينة أبوظبي. ويركز مشروع آخر برعاية الإمارات العربية المتحدة باسم «نور» Noor على التطبيقات التعليمية والإسلامية.
أما في قطر، فقد طور باحثون من جامعة حمد بن خليفة، ومعهد قطر لبحوث الحوسبة منصة «فنار»Fanar والنموذجين المرتبطين بها «فنار ستار» Fanar Star، و«فنار برايم» Fanar Prime. ومقاربة تقسيم وتحليل النصوص في نموذج «فنار»، الذي دُرب على تريليونات من وحدات التوكن، صُممت خصيصًا لتعكس ثراء تراكيب الكلمات والجمل العربية بالمعاني.
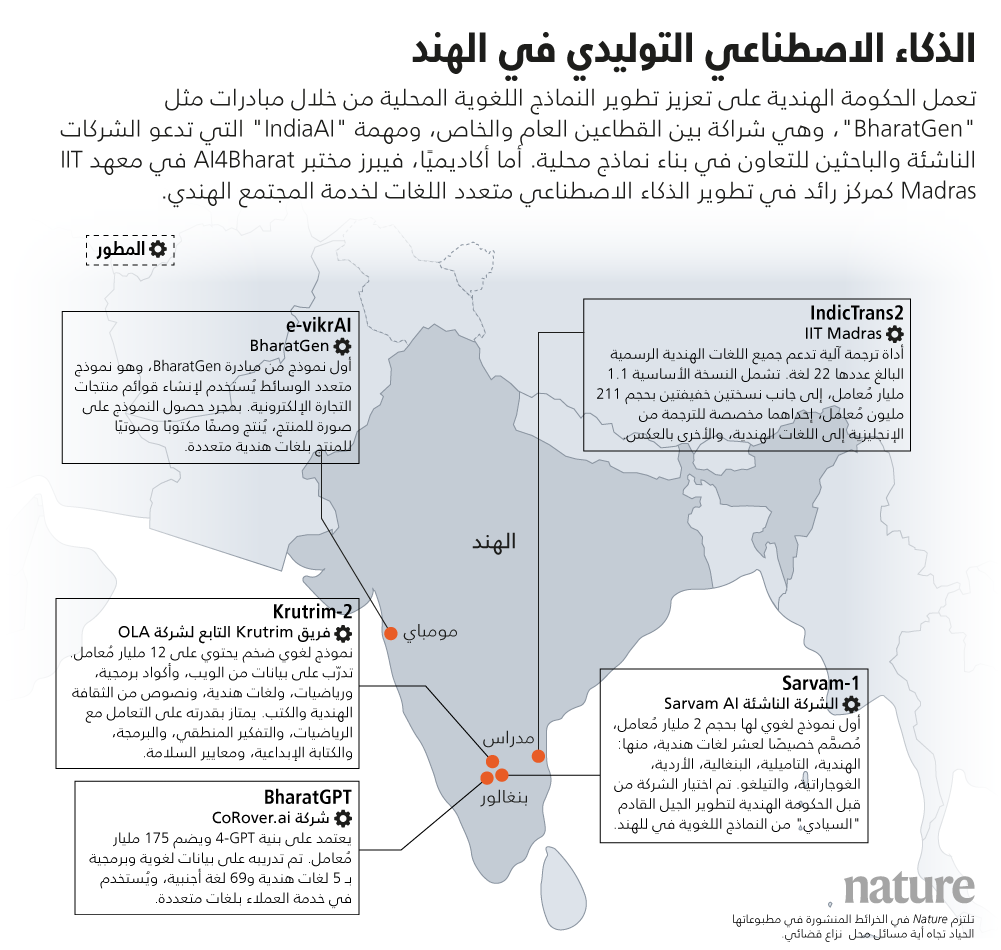
أيضًا برزت الهند كمركز رئيس لعمليات توطين أنظمة الذكاء الاصطناعي. إذ دشنت حكومة البلد عام 2024 مبادرة بشراكة بين القطاعين العام والخاص بقيمة 235 كرور (26 مليون يورو)، باسم «بْهارات جِن» BharatGen، تهدف إلى تصميم نماذج أساس (نوع من نماذج الذكاء الاصطناعي) تراعي التنوع الثقافي واللغوي الشاسع الذي تزخر به الهند. ويقود المشروع المعهد الهندي للتكنولوجيا في مومباي، بمشاركة من منظمات تابعة له في المدن الهندية حيدر أباد، وماندي وكنبور، وإندور ومدراس (تشيناي). ومن رحم المبادرة، خرج إلى النور أول منتج لها، وهو نموذج «إي-فيكراي» e-vikrAI القادر على استحداث توصيفات للمنتجات ومقترحات بأسعارها بناء على صورها بالعديد من لغات الهند. وانضمت إلى الركب عدة شركات ناشئة، مثل شركة «كروتريم» Krutrim التابعة لمجموعة «أولا» Ola، وشركة «كوروفر» CoRover، مبتكرة نموذج الذكاء الاصطناعي «بْهارات جي بي تي» BharatGPT. بينما أزاح المختبر الهندي التابع لشركة جوجل الستار عن نموذج «موريل» MuRIL، وهو نموذج لغوي كبير مُدرب حصريًا على اللغات الهندية. وقد تلقت مبادرة الحكومة الهندية أكثر من 180 مقترحًا من باحثين محليين وشركات ناشئة تطرح خططًا لتصميم بنية تحتية على مستوى البلاد لأنظمة الذكاء الاصطناعي والنماذج اللغوية الكبيرة. ووقع الاختيار على شركة «إيه آي سارفام» AI Sarvam الكائنة في بنغالور لبناء أول نموذج لغوي كبير هندي يحقق للبلد "سيادتها"، ويُزمع أن يتمتع بالطلاقة في عدة لغات هندية.
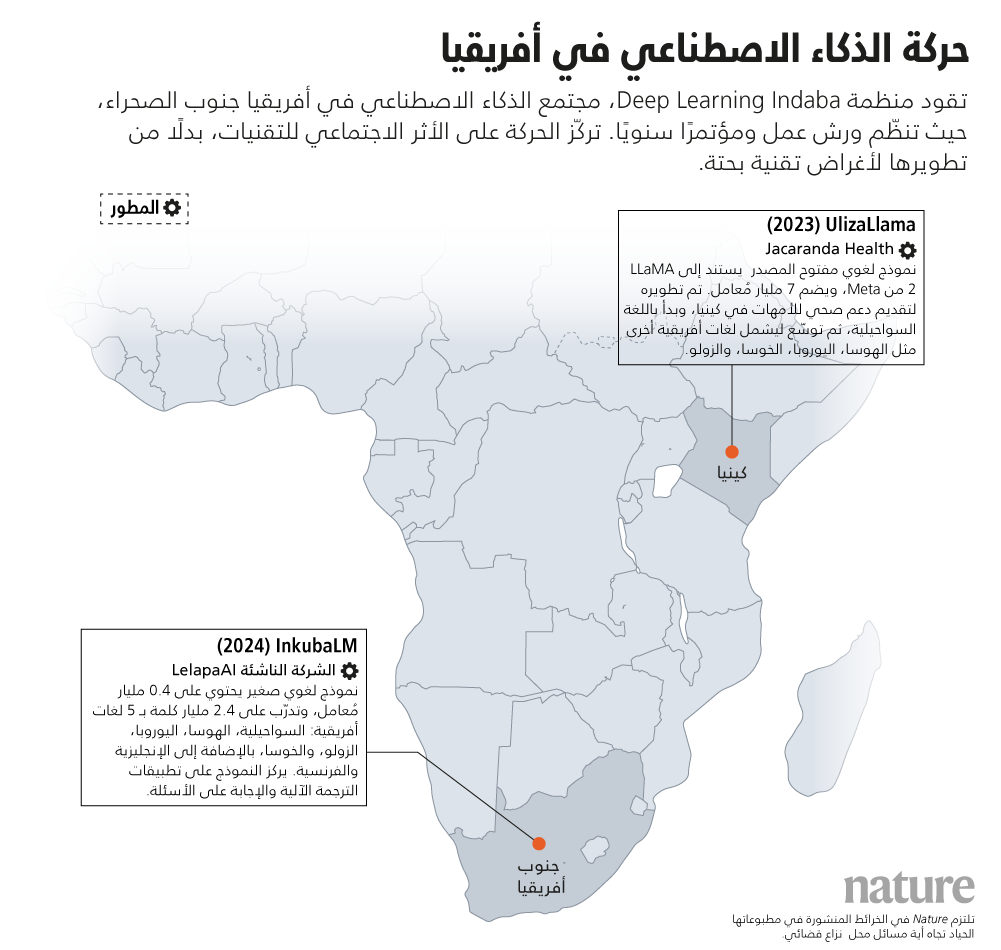
أما في إفريقيا، فقد انطلق جانب كبير من هذا الزخم من قاعدة شعبية. على سبيل المثال، خلق اتحاد «ماساكاني إن إل بي» وحركة «ديب ليرنينج إندابا» Deep Learning Indaba – وهي حركة أكاديمية إفريقية – ثقافة بحثية لا مركزية عبر القارة. ومن هنا، انبثقت شركة « ليلابا إيه آي» Lelapa AI الكائنة في مدينة جوهانسبرج، والتي أطلقت نموذج الذكاء الاصطناعي «إنكوبال إم» في سبتمبر من عام 2024. وينتمي هذا النموذج إلى فئة "النماذج اللغوية الصغيرة" (SLM)، ويركز على خمس لغات إفريقية واسعة الانتشار، هي: السواحيلية، ولغة شعوب الهوسا، وشعوب اليوروبا ولغة الزولو واللغة الخوسية.
وعنه يقول روزمان: "يقدم هذا النموذج باستخدام 0.4 مليار معامِل فقط أداءً مضاه لنماذج أكبر". وجدير بالذكر أن كفاءة النموذج وحجمه الصغير صُمما ليناسبا البنية التحتية الإفريقية على ما يعتريها من قصور، إلى جانب خدمة تطبيقات واقعية". مثال آخر على نماذج الذكاء الاصطناعي الإفريقية، هو نموذج «أوليزالاما» UlizaLlama، الذي طورته مؤسسة «جاكاراندا هيلث» Jacaranda Health الكينية من 7 مليارات معامِل لدعم النساء الحوامل وحديثات العهد بالأمومة بنظام ذكاء اصطناعي يتحدث اللغات الإفريقية الخمس سالفة الذكر.
والمشهد البحثي الهندي يضج بحيوية مماثلة. فنجد أن مختبر «إيه آي فور بْهارات» التابع للمعهد الهندي للتكنولوجيا في مدراس قد أصدر مؤخرًا نموذج «إنديك ترانس 2» IndicTrans 2، الذي يدعم الترجمة من وإلى 22 لغة من لغات الهند الرسمية. كذلك أصدرت الشركة الناشئة «سارفام إيه آي» أول منتجاتها من النماذج اللغوية الكبيرة العام الماضي وهو يدعم 10 من لغات الهند الرئيسة. وفي الوقت الحالي، تطور شركة «كيسان إيه آي» KissanAI، التي شارك في تأسيسها براتيك ديساي أدوات ذكاء اصطناعي توليدي لإرشاد الزُراع بلغتهم الأم.
معضلة البيانات
غير أن تصميم نماذج لغوية كبيرة للغات التي لا تحظى بتمثيل كاف تواجهه عقبات جسام. وعلى رأس هذه التحديات، تأتي ندرة البيانات اللازمة لتدريب هذه النماذج. وهو ما يؤكده تاباس كومار ميشرا، الأستاذ من المعهد الوطني للتكنولوجيا في مدينة روركيلا شرق الهند، قائلًا: "حتى مجموعات البيانات الهندية تُعد ضئيلة مقارنة بنظيرتها الصادرة باللغة الإنجليزية. من هنا، يُستبعد أن يحقق تدريب هذه النماذج من الصفر كفاءة الأداء ذاتها التي تتمتع بها النماذج المُدربة على بيانات بالإنجليزية".
ويؤيده في الرأي روزمان، الذي يضيف: "لا يصلح التدريب على مجموعات البيانات الضخمة كنموذج عمل يُحتذى به في حال اللغات الإفريقية. فببساطة لا يتوفر هذا القدر من البيانات التدريبية". وعليه، يبذل مع فريقه جهودًا رائده في مقاربات بديلة، منها اتباع إطار العمل المعروف باسم «إسيثو» Esethu، وهو بروتوكول يقضي بجمع مجموعات بيانات على نحو أخلاقي من خطاب الناطقين باللغات التي لا تحظى بتمثيل كاف، ثم توزيع العائد للنهوض بتطوير أدوات الذكاء الاصطناعي المخصصة لدعم هذه اللغات. وقد استخدمت المرحلة التجريبية من المشروع نصوصًا مكتوبة لخطاب متحدثين بالخوسية، تُكمِّله بيانات وصفية، بهدف تصميم تطبيقات صوتية.
وفي العالم العربي، انطلقت جهود مماثلة. فمثلًا، تُعد مجموعة بيانات شركة «كلاستر لاب» المؤلفة من 101 مليار كلمة عربية الأكبر على الإطلاق من نوعها، وهي مستقاة بدقة ومنقحة من شبكة الويب لدعم تدريب نماذج موجهة بالدرجة الأولى للعالم العربي.
ضريبة الانتشار المحدود
لكن برغم كل هذا الابتكار، تبقى هناك عقبات كؤود على الناحية العملية. فيقول ديساي، مؤسس شركة «كيسان إيه آي»: "العائد على هذه الاستثمارات منخفض". ورغم عِظم حجم سوق النماذج اللغوية الإقليمية، من يتمتعون بالقدرة الشرائية في هذه السوق يعتمدون إلى اليوم على الإنجليزية". وفي الوقت الذي تستقطب فيه شركات التقنيات الغربية بعضًا من ألمع العقول على مستوى العالم، ومنهم العديد من الهنود والأفارقة، كثيرًا ما يصطدم الباحثون في بلدان الجنوب العالمي بتحديات ممثلة في ضعف التمويل وعدم موثوقية البِنى التحتية الحوسبية في هذه البلدان، وغياب الأطر القانونية الواضحة الحاكمة لاستخدام البيانات وخصوصية المستخدمين".
وهو ما يشدد عليه حبيب قائلًا: "تبقى مشكلة غياب التمويل المستدام، وقلة المتخصصين، وعدم التكامُل بالدرجة الكافية مع المنظومات التعليمية والحكومية. وكل هذا لا بُد له أن يتغير".
رؤية جديدة للذكاء الاصطناعي
إلا أنه برغم العقبات، فلا شك أن رؤية جديدة ومختلفة لأنظمة الذكاء الاصطناعي آخذة في التبلور في الجنوب العالمي. وهي تنحاز إلى الفائدة العملية قبل اعتبارات الوجاهة، وإلى تمكين وإعطاء صوت للمجتمعات المحلية قبل الارتماء في أحضان شركات تفتقر إلى الشفافية.
ختامًا، تقول ناوالي: "ثمة اهتمام أكبر بحل مشكلات فعلية من واقع الأشخاص". بعبارة أخرى، عوضًا عن السعي وراء اقتناص أرفع الدرجات على مؤشر معايير ما، يستهدف باحثو الجنوب العالمي ابتكار أدوات تمت بصلة للواقع؛ للمزارعين والطلاب وأصحاب الشركات الصغيرة.
ولا غنى عن الشفافية هنا. في ذلك الصدد، يقول ماريفاتي: "تزعم بعض الشركات أن نماذجها مفتوحة المصدر، لكنها لا تفصح إلا عن معامِلات هذه النماذج، وليس البيانات في حد ذاتها. أما في حال نموذج «إنكوبال إم»، فنحن نفصح عن المعاملات والبيانات. إذ نسعى إلى تمكين الآخرين من البناء على ما حققناه، وتحسينه".
وفي سباق عالمي، لا يعتد في كثير من الأحيان إلا بسرعة معالجة البيانات ووحدات التوكِن، قد تبدو هذه الجهود متواضعة. لكن بالنسبة لمليارات الأشخاص ممن يتحدثون لغات لا تحظى بموارد كافية في بيانات نماذج الذكاء الاصطناعي الغربية، ترسم هذه الجهود مستقبلًا نملك فيه صوتًا في خطابنا مع هذه الأدوات.
doi:10.1038/nmiddleeast.2025.64
اشترك للحصول على النشرة الإلكترونية المحدّثة كل أسبوعين لكي تبقى على اطلاع بكافة المستجدات على الموقع.
التسجيل في خدمة النشرات الإلكترونية (بالإنجليزية)
تواصل معنا: