«جوجل» تطور نظام ذكاء اصطناعي يستطيع تشخيص المرض اعتمادًا على صوت السعال
29 April 2024
نشرت بتاريخ 6 يونيو 2023
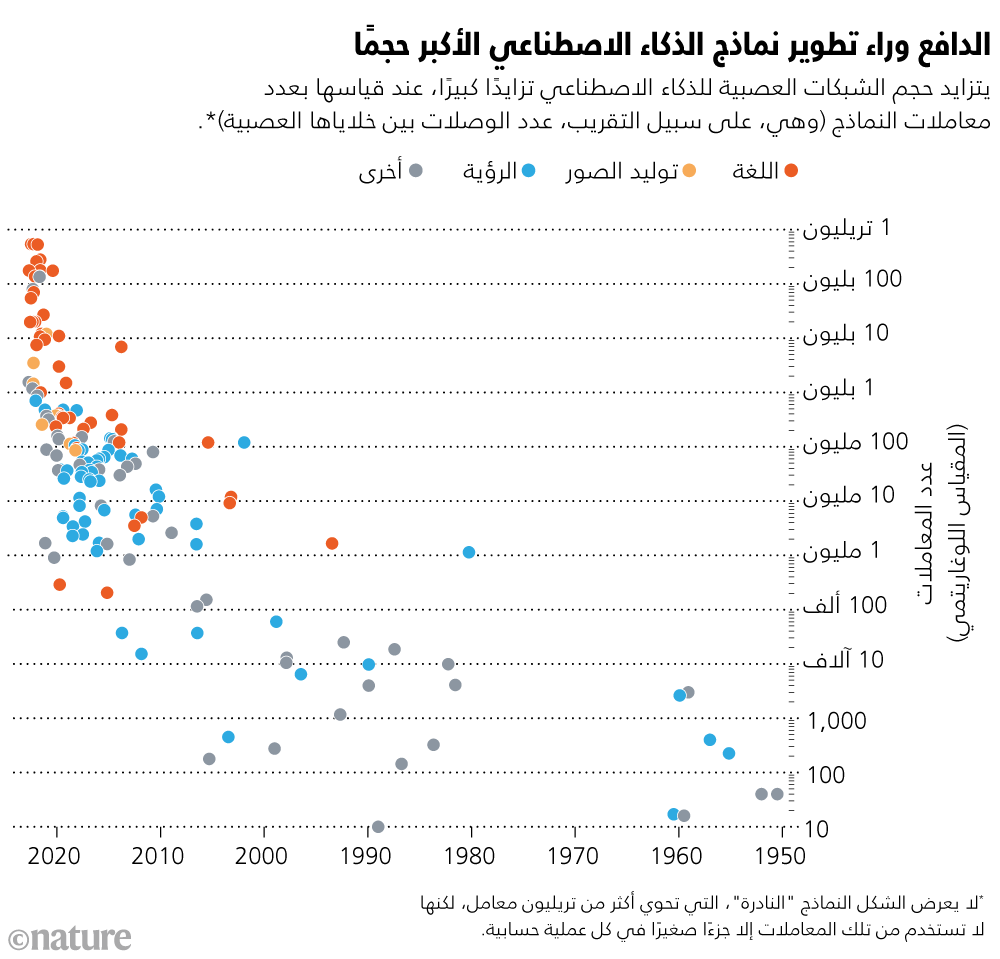
مع زيادة حجم نماذج الذكاء الاصطناعي التوليدية، ينادي بعض العلماء بأنظمة أقلَّ حجمًا وأكثر كفاءة في استهلاك الطاقة.
 copy.jpg)
تعد أنظمة الذكاء الاصطناعي القادرة على تأليف النصوص بطلاقة، مثل «تشات جي بي تي» ChatGPT الذي طوَّرَتْه شركة «أوبن إيه آي» OpenAI، أحدث ما أثمرت عنه التكنولوجيا في هذا الميدان. ولكن عندما تُطرح على هذه النماذج اللغوية الكبيرة (LLMs) مسائل رياضية يتطلب حلها قدرًا من التفكير، فإنها غالبًا ما تتعثر في التوصل إلى الإجابة. إليك، على سبيل المثال، مسألة الجبر الآتية:
خطٌّ موازٍ للخط الذي تعبِّر عنه المعادلة: ص =4س + 6، ويمر عبر النقطتين (5 و10). أوجد الإحداثي الصادي للنقطة التي يقطع فيها هذا الخط محور الصادات؟
تصيب النماذج اللغوية الكبيرة في الإجابة عن مثل هذه النوعية من الأسئلة حينًا، وتخطئ أحيانًا. في أحد الاختبارات المبكرة لقياس القدرات المنطقية للأداة «تشات جي بي تي»، سجل هذا الروبوت نسبة 26% فقط عندما طُرحت عليه عينة من الأسئلة من مجموعة بيانات تُدعى «ماث» MATH تضم مسائل رياضية تناسب مستوى طلاب المرحلة الثانوية1.
كان ذلك متوقعًا؛ فبالنظر إلى النص المُدخَل، فإن ما تفعله النماذج اللغوية الكبيرة ببساطة هو تأليف نص جديد وفقًا لنماذج الانتظام الإحصائي في الكلمات والرموز والجُمل التي تشكل بيانات التدريب الخاصة بالنموذج. بالطبع سيكون الأمر مذهلًا لو أن تعلُّم الأنماط اللغوية فحسب يمكن أن يتيح للنماذج اللغوية الكبيرة محاكاة عملية الاستدلال الرياضي بشكل موثوق.
ولكن في يونيو 2022، كان أحد النماذج اللغوية الكبيرة من إصدار شركة «جوجل»، يُسمَّى «مينيرفا» Minerva، قد تحدى بالفعل تلك التوقعات إلى حدٍّ ما. أحرز النموذج «مينيرفا» 50% من درجات الأسئلة في مجموعة البيانات «ماث» المذكورة أعلاه2؛ وهي النتيجة التي أصابت بعض الباحثين في مجال الذكاء الاصطناعي بالصدمة.
يقول سيباستيان بوبيك، اختصاصي التعلم الآلي في شركة «مايكروسوفت ريسيرش» Microsoft Research، التي يقع مقرها في مدينة ريدموند بواشنطن: "يدور الحديث الآن في الأوساط البحثية عن كيف أن هذا الأمر يبدو مذهلًا".
يتمتع نموذج «مينيرفا» بميزة تتمثل في أنه قد دُرِّب على نصوص متعلقة بمجال الرياضيات. لكن دراسة «جوجل» أشارت إلى سبب آخر مهم يقف وراء الأداء الجيد الذي قدمه النموذج، ألا وهو حجمه الضخم. بلغ حجم النموذج ما يقرب من ثلاثة أضعاف حجم «تشات جي بي تي».
تشير النتائج التي حققها «مينيرفا» ضمنيا إلى أمر لطالما كان موضع شك من جانب بعض الباحثين؛ وهو أن تدريب النماذج اللغوية كبيرة الحجم، وتغذيتها بكمية أكبر من البيانات، من الممكن أن يمنح تلك النماذج القدرة على حل مهام وواجبات يُفترَض أنها تتطلب استدلالًا منطقيا، وذلك فقط من خلال التعرف على الأنماط. وإذا كان الأمر كذلك، فإن بعض باحثي الذكاء الاصطناعي يقولون إن استراتيجية "الأكبر هو الأفضل" قد تتيح لنا طريقًا نحو ذكاء اصطناعي يتميز بالقوة.
غير أن ثمة أسبابًا للشك في هذه الأطروحة؛ فما زالت النماذج اللغوية الكبيرة ترتكب أخطاءً فادحة، ويشير بعض العلماء إلى أن ما يحدث هو فقط أن النماذج الأكبر حجمًا يتحسن أداؤها في الإجابة عن المسائل والاستفسارات التي تقع ضمن نطاق علاقات الارتباط في بياناتها التدريبية، وليس أنها تكتسب القدرة على الإجابة عن أسئلة جديدة تمامًا.
تشهد الفترة الراهنة جدلا دائرا فيما يخص آفاق الذكاء الاصطناعي. حققت الشركات التجارية نتائج أفضل باستخدام نماذج ذكاء اصطناعي ذات حجم أكبر؛ ولذا فهي تطرح الآن نماذج لغوية أكبر حجمًا من أي وقت مضى؛ بل إن تكلفة النموذج الواحد قد تصل إلى ملايين الدولارات فيما يخص التدريب والتشغيل (انظر: "الدافع وراء تطوير نماذج الذكاء الاصطناعي الأكبر حجمًا"). إلا أن هذه النماذج لها سلبياتها الكبيرة؛ فإلى جانب الخوف من أنه لا يمكن الوثوق بمخرجات تلك النماذج، وأنها ربما تؤدي إلى تفاقم انتشار المعلومات الخاطئة والمضللة، فهي أيضًا باهظة الثمن وتستهلك كميات هائلة من الطاقة.
يرى منتقدو النماذج اللغوية الكبيرة أن الأحجام الكبيرة منها لن تتمكن، في نهاية المطاف، من محاكاة أو اكتساب المهارات التي تتيح لها الإجابة عن مسائل تتطلب استدلالًا منطقيا بشكل متسق. بل إن بعض العلماء يقولون إن نماذج الذكاء الاصطناعي الأصغر حجمًا والأوفر استهلاكًا للطاقة تمثل السبيل البديل لإحراز تقدم في هذا المجال؛ وهي فكرة مستوحاة بصورة جزئية من الطريقة ذاتها التي يستخدمها الدماغ البشري على ما يبدو للتعلم والربط بين الأشياء.
هل الأكبر هو الأفضل؟
يجدر القول إن النماذج اللغوية الكبيرة، مثل «تشات جي بي تي» و«مينيرفا»، هي شبكات عملاقة من الوحدات الحوسبية (تسمى أيضًا الخلايا العصبية الاصطناعية) مرتَّبة في طبقات. يُقاس حجم النماذج اللغوية الكبيرة بعدد المعاملات التي تحويها، ويمكن تعريف تلك المعاملات بأنها القيم القابلة للتعديل التي تصف قوة الارتباط والاتصال بين الخلايا العصبية. يتضمن تدريب هذه الشبكات تكليفها بالتنبؤ بأجزاء مخفاة من جمل معروفة وكذلك تبديل هذه المعاملات وتعديلها بحيث يتحسن أداء الخوارزمية في المرات التالية بعض التحسُّن.
إذا كررنا هذه العملية عبر مليارات الجمل المكتوبة من قبل البشر، فإن الشبكة العصبية تتمكن من تعلم التمثيلات الداخلية التي تُشكل الكيفية التي يستخدمها البشر لكتابة اللغة. في هذه المرحلة، يُقال إن النموذج اللغوي الكبير قد خاض تدريبًا مسبقًا؛ حيث تتمكن معاملاته من استيعاب البنية الإحصائية للغة المكتوبة التي صادفتها أثناء التدريب، بما في ذلك جميع الحقائق والتحيزات والأخطاء الموجودة في النصوص. ويمكن بعد ذلك "مواءمة" ذلك النموذج لمعالجة بيانات متخصصة.
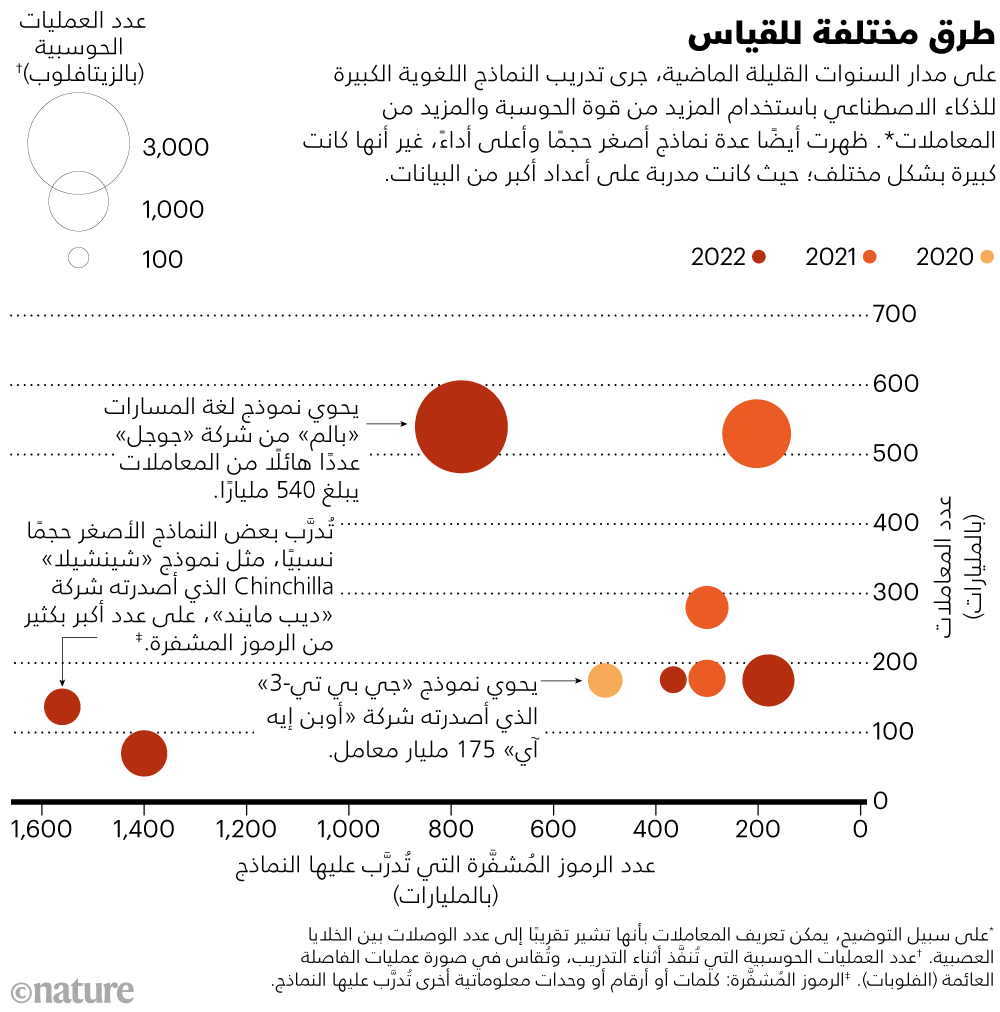
على سبيل المثال، في إطار تطوير نموذج «مينيرفا»، استهل الباحثون عملهم بنموذج لغة المسارات، المعروف اختصارا باسم «بالم» PaLM من إصدار شركة «جوجل»، الذي يحوي 540 مليار مُعامل، والذي دُرِّب مسبقًا على مجموعة بيانات تتكون من 780 مليار رمز مُشفَّر3. يمكن أن يكون الرمز المُشفَّر كلمة أو رقمًا أو أية وحدة معلوماتية. في حالة النموذج «بالم»، جُمعت تلك الرموز المُشفَّرة من مستندات وكتب ورموز موجودة على شبكة الإنترنت، سواءٌ باللغة الإنجليزية أو بلغات عديدة. كان «مينيرفا» بمثابة نتاج لعملية مواءمة نموذج «بالم» مع عشرات المليارات من الرموز المُشفَّرة المأخوذة من أوراق بحثية علمية وصفحات ويب ذات صلة بالرياضيات.
يمكن لنموذج «مينيرفا» الاستجابة لمحفزات مثل: ما أكبر مضاعف للعدد 30، بشرط أن يكون أقل من 520؟ على ما يبدو، فإن النموذج اللغوي الكبير يفكر في الخطوات، ومع ذلك فإن كل ما يفعله هو تحويل الأسئلة إلى تتابُع من الرموز المُشفَّرة، وإنشاء رمز مُشفَّر لاحِق يكون مقبولًا من الناحية الإحصائية، وإلحاقه بالتتابع الأصلي، وإنشاء رمز مُشفَّر آخر، وهكذا دواليك؛ فيما يُسمَّى بعملية الاستدلال.
قام باحثو شركة «جوجل» بمواءمة ثلاثة أحجام من نموذج «مينيرفا» باستخدام ثلاثة نماذج مدربة مسبقًا من «بالم» بعدد معاملات تبلغ 8 مليارات و62 مليار و540 مليار على التوالي. تحسن أداء «مينيرفا» مع زيادة الحجم. في مجموعة بيانات «ماث» عموما، وصل معدل الدقة لأداء النموذج الأصغر حجمًا إلى 25%، بينما وصل النموذج متوسط الحجم إلى 43%، وتخطى النموذج الأكبر حجمًا نسبة 50%.
استخدم النموذج الأكبر أيضًا أقل قدر من بيانات المواءمة؛ فقد جرت مواءمته مع 26 مليار رمز مُشفَّر فقط، بينما كان النموذج الأصغر يبحث في 164 مليار رمز مُشفَّر. إلا أن النموذج الأكبر استغرق شهرًا لأجل مواءمته باستخدام أجهزة متخصصة ذات سعة حوسبة تبلغ ثمانية أضعاف سعة الحوسبة المستخدمة مع النموذج الأصغر، الذي استغرقت مواءمته أسبوعين فقط. نظريًا، كان من المفترض مواءمة النموذج الأكبر لمعالجة عدد أكبر من الرموز المُشفَّرة، بحسب قول إيثان داير من شركة «جوجل ريسيرش» Google Research في ماونتن فيو بولاية كاليفورنيا، وهو أيضًا عضو في فريق نموذج «مينيرفا». كان من الممكن أن يؤدي ذلك إلى تحسين أداء النموذج، إلا أن أفراد الفريق رأوا أنه لم يكن ممكنا تحمل التكلفة الحوسبية.
قوانين الحجم
كان تحقيق النموذج الأكبر حجمًا من «مينيرفا» لأفضل معدلات الأداء يتماشى مع الدراسات التي كشفت عن قوانين الحجم؛ وهي عبارة عن مجموعة من القواعد التي تحكم مسألة تحسن الأداء اتساقًا مع حجم النموذج. أوضحت دراسة أُجريت في عام 2020 أن التحسن في أداء النماذج كان مرتبطًا بأحد أمور ثلاثة: معاملات أكثر عددًا، أو عدد أكبر من بيانات التدريب، أو مزيد من "العمليات الحوسبية" (ويُقصد بها عدد عمليات الحوسبة المنفذة أثناء التدريب)4. كان الأداء يتدرج بشكل يتبع قانون الرفع، ما يعني أنه قد تحسن، على سبيل المثال، في صيغة رقم مرفوع لعدد المعاملات.
على أن الباحثين لا يعرفون بالضبط السبب وراء ذلك. تقول إيرينا ريش، اختصاصية علوم الكمبيوتر بجامعة مونتريال وميلا ومعهد كيبيك للذكاء الاصطناعي في مونتريال بكندا: "هذه القوانين تجريبية بحتة".
وللحصول على أفضل النتائج، أشارت الدراسة المنشورة في عام 2020 إلى أنه مع مضاعفة بيانات التدريب، فإنه من المفترض زيادة حجم النموذج بواقع خمسة أضعاف. لكن الأعمال التي نُفِّذت العام الماضي ساهمت مساهمة طفيفة في تنقيح هذا الافتراض. في مارس، أعلنت شركة «ديب مايند» DeepMind للذكاء الاصطناعي، ومقرها لندن، أن الحل الأمثل يتلخص في زيادة حجم النموذج وبيانات التدريب معًا، وأن النماذج الأصغر حجمًا، المدربة على المزيد من البيانات، يكون أداؤها أفضل من النماذج الأكبر حجمًا لكنها مدربة على بيانات أقل عددًا5 (انظر: "طرق مختلفة للقياس"). على سبيل المثال، يحتوي نموذج «شينشيلا» Chinchilla الذي ابتكرته «ديب مايند» على 70 مليار معامل، ودُرِّب على 1.4 تريليون رمز مُشفَّر، في حين دُرِّب النموذج «جوفر» Gopher، الذي يبلغ عدد معاملاته 280 مليارًا على 300 مليار رمز مُشفَّر. يتفوق «شينشيلا» على «جوفر» في أداء المهام المصممة لتقييم ما يتعلمه النموذج اللغوي الكبير.
اعتمد العلماء في «ميتا ريسيرش» على المفهوم ذاته في فبراير من خلال نموذج الذكاء الاصطناعي اللغوي الكبير من «ميتا»، المعروف اختصارًا باسم «لاما» LLaMA، والذي يتميز بصغر حجم معاملاته والمدرب على ما يصل إلى 1.4 تريليون رمز مُشفَّر. تفوَّق إصدار «لاما» الذي يحوي 13 مليار معامل في الأداء على سلف «تشات جي بي تي»، المعروف باسم «جي بي تي-3» GPT-3 (175 مليار معامل)، كما يقول الباحثون، في حين أن نسخة الإصدار ذاته التي تحوي 65 مليار معامل كانت منافسة لنموذج «شينشيلا» وكذلك لنموذج «بالم» (انظر: go.nature.com/3kje2fj).
في أكتوبر الماضي، أفاد إيثان كاباليرو من جامعة ماكجيل في مونتريال، بالاشتراك مع ريش وآخرين، عن اكتشاف علاقات أكثر تعقيدًا بين حجم النموذج وأدائه6. يقول الباحثون إنه في بعض الحالات، يمكن لقوانين الرفع المتعددة أن تحكم الكيفية التي يتدرج بها الأداء صعودًا وهبوطًا بالتوازي مع حجم النموذج.
على سبيل المثال، في أحد السيناريوهات الافتراضية التي وضعها الباحثون بالتناسب مع معادلة عامة، لاحظوا أن الأداء يتحسن أولًا بشكل تدريجي ثم بسرعة أكبر بالتوازي مع حجم النموذج، إلا أنه يتراجع بعد ذلك قليلًا مع استمرار عدد المعاملات في الزيادة، قبل أن يأخذ في التحسن مرة أخرى من جديد. من هذا المنطلق، فإن خصائص كل نموذج وكيفية تدريبه هي التي تملي خصائص هذه العلاقة المعقدة. يأمل الباحثون أن يتمكنوا في نهاية المطاف من التنبؤ بذلك الأمر بشكل استباقي عند توسيع نطاق نموذج لغوي كبير بعينه.
ثمة اكتشاف نظري مستقل يدعم أيضًا السعي نحو إنشاء نماذج أكبر؛ وهو "قانون المتانة" لتعلم الآلة، الذي قدمه بوبيك وزملاؤه في عام 72021. يكون النموذج متينًا إذا ظلت إجاباته متسقة، حتى لو طرأ على مدخلاته بعض الاختلافات الصغيرة. بعض أنظمة الذكاء الاصطناعي تحيط بها سمعة سيئة، تتمثل في هشاشتها. فإذا دُرِّبت على التعرف على صور الكلاب، على سبيل المثال، فإنها ستخطئ في تصنيف أية صورة اختبارية تتعرض لأي تشويش ولو طفيف، رغم أن ذلك التشويش لن ينطلي على البشر.
وكلما زادت متانة تقنيات الذكاء الاصطناعي، كانت القدرة على تعميمها على البيانات غير المرئية أفضل. أوضح بوبيك وزملاؤه بطريقة رياضية أن زيادة عدد المعاملات في نموذجٍ ما يزيد من متانته، ومن ثمَّ من القدرة على تعميمه. يقول بوبيك إن القانون يثبت أن توسيع نطاق النموذج ضروري لتعميمه، لكنه لا يثبت أن ذلك يُعد كافيًا. ومع ذلك، يُستخدَم هذا الزعم حاليًا لتبرير التحرك نحو نماذج أكبر حجمًا، كما يقول بوبيك، الذي يضيف: "وهو ما أعتقد أنه أمر معقول".
استفاد نموذج «مينيرفا» أيضًا من ابتكار مهم يُسمَّى تحفيز سلاسل الأفكار. يستهل المستخدم سؤاله بنص يتضمن بضعة أمثلة للأسئلة والحلول متضمنةً الاستدلال المنطقي الذي قاد إلى التوصل إلى الإجابات؛ وهو ما يدل على سلسلة نمطية من الأفكار. أثناء عملية الاستدلال، يستلهم النموذج اللغوي الكبير إشاراته من هذا السياق ويقدم إجابته بشكل متدرج خطوةً بخطوة يشبه الاستدلال المنطقي بشكل يثير الدهشة. لا تتطلب هذه العملية إجراء تحديثات لمعاملات النموذج، ومن ثمَّ لا تتضمن قوة الحوسبة الإضافية التي تحتاجها عملية المواءمة.
تظهر القدرة على الاستجابة لمحفزات سلاسل الأفكار فقط لدى النماذج اللغوية الكبيرة التي تحتوي على أكثر من مئة مليار معامل. ساعدت هذه الاكتشافات النماذج الأكبر على التحسن وفقًا لقوانين الحجم التجريبية، كما يقول بليز أجويرا إي أركاس من شركة «جوجل ريسيرش»، التي يقع مقرها في سياتل بواشنطن، الذي يضيف: "أداء النماذج الأكبر آخذٌ في التحسن مرةً تلو الأخرى".
مخاوف منطقية
فرانسوا شوليت، باحث الذكاء الاصطناعي في شركة «جوجل» في ماونتن فيو، هو من بين المشككين الذين يرون أنه مهما بلغ حجم النماذج اللغوية الكبيرة، فإنها لن تتمكن أبدًا من امتلاك القدرة على التفكير (أو حتى محاكاة التفكير) بالدرجة المطلوبة لحل المشكلات الجديدة بشكل موثوق. فالنماذج اللغوية الكبيرة لا تستطيع، على ما يبدو، سوى التفكير باستخدام قوالب صادفَتْها من قبل، سواء من خلال بيانات التدريب أو عبر المحفزات اللغوية، كما يقول شوليت، الذي يضيف: "لا يمكن لتلك النماذج أن تستوعب على الفور شيئًا لم تصادفه من قبل".
غير أن أفضل ما يمكن للنماذج اللغوية الكبيرة أن تفعله هو استيعاب كميات هائلة من بيانات التدريب بحيث تسمح لها الأنماط الإحصائية للغة وحدها بالرد على الأسئلة بإجابات قريبة جدًا مما صادفته تلك النماذج بالفعل.
ومع ذلك، يرى أجويرا إي أركاس أنه يبدو أن النماذج اللغوية الكبيرة قد اكتسبت بالفعل بعض القدرات المدهشة التي لم تتدرب عليها تحديدًا. يشير أركاس على وجه الخصوص إلى الاختبارات المصممة لإظهار ما إذا كان لدى الشخص ما يُسمى بنظرية العقل؛ بمعنى القدرة على التنظير أو تقييم الحالات الذهنية للآخرين. لنأخذْ مثالًا بسيطًا على ذلك: تضع آليس نظارتها في الدُرج، ثم يأتي بوب، دون علم آليس، ويخفي النظارة تحت الوسادة، فأين ستبحث آليس عن نظارتها أولًا؟ إذا طُرِح هذا السؤال على طفل، فإن الغرض منه يكون اختبار ما إذا كان هذا الطفل يفهم أن آليس لديها معتقداتها الخاصة، التي قد لا تتفق مع ما يعرفه ذلك الطفل.
في التجارب التي أجراها أجويرا إي أركاس على نموذج لغوي كبير آخر من ابتكار شركة «جوجل» يُسمَّى «لامدا» LaMDA، وهو اختصار لنموذج اللغة لتطبيقات الحوار، وجد الباحث أن «لامدا» قدم إجابات صحيحة في محادثات موسعة من هذا النوع. بحسب قول أركاس، كان ذلك يشير إلى قدرة هذا النموذج اللغوي الكبير على وضع تصور داخلي لنوايا الآخرين. يقول عن ذلك: "هذه النماذج التي لا تفعل سوى التنبؤ بالتسلسلات ينمو لديها نطاق غير عادي من القدرات، بما في ذلك نظرية العقل". ولكن أركاس يُسلِّم بأن هذه النماذج عرضة للخطأ، كما أنه أيضًا غير متأكد مما إذا كان الحجم وحده، رغم أنه يبدو ضروريًا، كافيا للتفكير بشكل موثوق.
يقول شوليت إنه حتى عندما تصل النماذج اللغوية الكبيرة إلى إجابات صحيحة، فإن ذلك لا يقوم على أساس من الفهم. ويضيف قائلا: "إذا حاولت ولو قليلًا التفكر في الأمر، لاتَّضح لك على الفور أنها ليست سوى جعجعة فارغة. لا يمتلك «تشات جي بي تي» نموذجًا لما يتحدث عنه. لذا، يبدو الأمر كما لو كنت تشاهد عرضًا للدُّمى، ويدور بخلدك أنها حية ترزق".
تقول ميلاني ميتشل، التي تدرس تجريد المفاهيم وعقد المقارنات في أنظمة الذكاء الاصطناعي في معهد سانتا فيه بولاية نيو مكسيكو، إن النماذج اللغوية الكبيرة لا تزال حتى الآن ترتكب أخطاءً سخيفة لا يمكن أن يرتكبها البشر مطلقًا. وقد ساهم ذلك في تأجيج عديد من المخاوف بشأن مدى سلامة إطلاق العنان للنماذج اللغوية الكبيرة في المجتمع دون وضع وسائل للحماية.
وتضيف ميتشل أن ثمة مشكلة في الجدل الدائر بشأن ما إذا كان بإمكان النماذج اللغوية الكبيرة معالجة مشكلات جديدة تمامًا لم تصادفها من قبل؛ وهي أننا لا نمتلك الوسيلة اللازمة لإجراء اختبار شامل لهذه القدرة. تقول عن ذلك: "المعايير المرجعية المتوفرة لدينا حاليًا ليست كافية؛ فهي لا تساعد على دراسة الأمور بشكل منهجي. حقيقةً، نحن لا نعرف حتى الآن كيف نقوم بذلك العمل".
مشاكل الحجم
بينما يظل الجدل دائرًا، هناك بالفعل مخاوف ملحة بشأن الاتجاه نحو نماذج لغوية أكبر حجمًا. من بين هذه المخاوف أن مجموعات البيانات والقوة الحوسبية والنفقات الداخلة في تدريب النماذج اللغوية الكبيرة ذات الحجم الضخم تقصر تطور تلك النماذج - ومن ثمَّ توجهها البحثي – على الشركات التي تمتلك موارد حوسبية هائلة. لم تعلق شركة «أوبن إيه آي» على التكلفة التي انطوت عليها عملية إنشاء «تشات جي بي تي»، إلا أن مصادر أخرى قدرت بناءً على الجوانب الحوسبية ذات الصلة أنه يفترض أن التدريب المسبق للنموذج «جي بي تي-3»، وهو سلف «تشات جي بي تي»، قد تكلف أكثر من أربعة ملايين دولار أمريكي. ومن المحتمل أن «أوبن إيه آي» تتكلف حاليًا ملايين الدولارات بصفة شهرية لتشغيل «تشات جي بي تي»؛ وذلك يرجع إلى عدد الاستفسارات التي يرد عليها روبوت الدردشة المجاني في الوقت الراهن. يقول بوبيك: "لقد قطعنا بالفعل مسافة طويلة داخل أعماق هذا النظام. ثمة قلة قليلة من الشركات التي لديها نماذج يزيد عدد معاملاتها عن مائة مليار".
بدأت الحكومات في التدخل بتوفير الدعم الذي من شأنه توسيع ساحة اللعب. في يونيو من العام الماضي، نجح فريق دولي يضم قرابة ألف متطوع من الأكاديميين، بتمويل من الحكومة الفرنسية ومن شركة أمريكية للذكاء الاصطناعي تحمل اسم «هاجِنج فيس» Hugging Face وممولين آخرين، في تدريب نموذج يُسمَّى «بلوم» BLOOM على حوالي 175 مليار معامل، بقيمة تعادل سبعة ملايين دولار من وقت الحوسبة8. وفي نوفمبر، منحت وزارة الطاقة الأمريكية وقتًا للحوسبة الفائقة لمشروع مقدَّم من ريش وزملائها، لبناء نماذج كبيرة بهدف دراسة سلوكياتها. تقول ريش: "نأمل أن ندرب نموذجًا شبيهًا بنموذج «شينشيلا» الذي يحوي 70 مليار معامل، ليس بالضرورة أن يكون الأكبر، ولكننا نريده أن يصبح نوعًا ما النموذج الذي يتصاعد أداؤه بشكل أكثر فعالية".
وبغض النظر عمن سيبني تلك النماذج اللغوية الكبيرة، فإنها تثير أيضًا مخاوف أخرى بشأن استهلاك الكهرباء. على سبيل المثال، ذكرت شركة «جوجل» أن تدريب النموذج «بالم» استغرق حوالي 3.4 جيجاواط/ساعة على مدار شهرين تقريبًا. يمثل هذا القدر نفس كمية الطاقة التي تستهلكها حوالي ثلاثمائة أسرة أمريكية سنويا. نفذت «جوجل» عملية تدريب النموذج «بالم» في مركز البيانات الخاص بها في أوكلاهوما، والذي تقول إنه يعمل باستخدام طاقة خالية من الكربون بنسبة 89%، ويُدار في الغالب باستخدام طاقة الرياح ومصادر طاقة متجددة أخرى. غير أن دراسة استقصائية لنماذج الذكاء الاصطناعي في الصناعة أظهرت أن غالبية النماذج يجري تدريبها باستخدام شبكات الكهرباء المحلية التي لا يزال معظمها يعمل بالوقود الأحفوري9.
أما ما يشغل بال شوليت، فإنه مع بدء العديد من الشركات في تدريب نماذج أكبر واستخدامها، يمكن أن يؤدي ذلك إلى استنفاد مزيد من طاقة الكهرباء. يقول شوليت: "ستحاول كل شركة تقنية كبيرة الآن نشر النماذج اللغوية الكبيرة في منتجاتها، بغض النظر عما إذا كانت تلك الفكرة مقبولة أم لا".
هل من نماذج أذكى وأصغر حجما؟
يرى كثير من العلماء أن الحاجة ملحَّة إلى تقليل استهلاك النماذج اللغوية الكبيرة للطاقة؛ وذلك لجعل الشبكات العصبية أصغر حجمًا، وأكثر كفاءة، وربما أشدّ ذكاءً. وإضافة إلى تكاليف الطاقة المستهلكة في تدريب النماذج اللغوية الكبيرة (والتي، على الرغم من كونها ضخمة، فإنها غير متكررة)، يمكن أن يزداد استهلاك الطاقة اللازمة للاستدلال - حيث تجيب النماذج اللغوية الكبيرة عن الأسئلة والاستفسارات - مع زيادة عدد المستخدمين. لم تعلق الشركات الكبرى في مجال التكنولوجيا على تكاليف الاستخدام الخاصة بنماذجها اللغوية. ومع ذلك، كشفت شركة «هاجِنج فيس» أنه عندما نُشر نموذجها «بلوم» على منصة «جوجل كلاود» Google Cloud لمدة 18 يومًا، وأجاب في تلك الفترة عن 230,768 استفسارًا (وهو عدد يقل بكثير عما حققه «تشات جي بي تي»، الذي وصل إلى مئة مليون مستخدم نشط شهريًا في فبراير)، استهلك النموذج، في المتوسط، 1664 واط10.
على سبيل المقارنة، نجد أن أدمغتنا البشرية أشد تعقيدًا وأكبر حجمًا من أي نموذج لغوي كبير؛ حيث تحتوي على 86 مليار خلية عصبية وما يقرب من 100 تريليون وصلة مشبكية. غير أن الدماغ البشري يستهلك ما بين 20 و50 واط من الطاقة، حسبما يقول فريدمان زينكي من معهد فريدريش ميشر للبحوث الطبية الحيوية في بازل بسويسرا.
لذلك يأمل بعض الباحثين في أن تقدِّم محاكاة جوانب الدماغ البشرية يد المساعدة للنماذج اللغوية الكبيرة والشبكات العصبية الأخرى بحيث تصبح أصغر حجما وأكثر ذكاءً وكفاءة.
قد يكون أحد المصادر التي يعود إليها ذكاء الدماغ البشري وكفاءته بشكل عام هو وصلاته المتكررة أو الراجعة. تعد النماذج اللغوية الكبيرة، في الأساس، بمثابة شبكات "تغذية أمامية"؛ ما يعني أن المعلومات تتدفق في اتجاه واحد: من المدخلات، عبر طبقات النماذج اللغوية الكبيرة، إلى المخرجات. أما الدماغ البشري فيعمل بتوصيلات مختلفة. على سبيل المثال، في النظام البصري لدى البشر، تربط الخلايا العصبية مناطق الدماغ التي تتلقى المعلومات البصرية أولًا بالمناطق التي تقع وراءها. ومع ذلك، فهناك أيضًا وصلات تغذية راجعة تتيح نقل المعلومات بين الخلايا العصبية في الاتجاه العكسي. تقول ميتشل: "ربما يبلغ عدد وصلات التغذية الراجعة عشرة أضعاف وصلات التغذية الأمامية في النظام البصري [البشري]"، إلا أن النماذج اللغوية الكبيرة لا تمتلك وصلات تغذية راجعة.
تُسمى الشبكات العصبية الاصطناعية التي تجمع بين كلٍ من وصلات التغذية الأمامية والراجعة في العموم الشبكات العصبية المتكررة (RNNs). يمكن لمثل هذه الشبكات (على عكس أنظمة النماذج اللغوية الكبيرة ذات التغذية الأمامية) تمييز الأنماط في البيانات التي تتغير بمرور الوقت. يقول كاناكا راجان، عالم الأعصاب الحاسوبية بكلية آيكان للطب في ماونت سيناي بمدينة نيويورك، إن ذلك يمثل "أساسا للكيفية التي تستخدمها جميع الذكاءات الطبيعية في استكشاف العالم وفي التعلم". غير أن الشبكات العصبية المتكررة تجلب معها تحديات عدة، كما يقول راجان. على سبيل المثال، تتميز تلك الشبكات بأنها صعبة وبطيئة في تدريبها، ما يجعل من الصعب زيادة حجمها ليصل إلى حجم النماذج اللغوية الكبيرة الحالية.
ثمة سبب آخر ترجع إليه كفاءة الأدمغة البشرية؛ وهو أن الخلايا العصبية البيولوجية غالبًا ما تكون ساكنة؛ حيث تشهد زيادة في النشاط فقط من حين لآخر. على النقيض من ذلك، تُصمَّم الخلايا العصبية الاصطناعية في معظم الشبكات العصبية على أساس العمل باستمرار. يدرس الباحثون حاليًا الخلايا العصبية الاصطناعية التي تتعرض لزيادة في نشاطها (تحاكي الخلايا الحقيقية)، ولكن من الصعب مواءمة الخوارزميات التي تدرب الشبكات العصبية القياسية لتناسب الشبكات التي تستخدم الخلايا العصبية النشطة. ومع ذلك، أظهرت الأبحاث التي تستخدم مجموعات بيانات صغيرة الحجم (على سبيل المثال، عشرة آلاف تسجيل صوتي استخدمت لتدريب إحدى الشبكات على التعرف على الأرقام المنطوقة) أن الشبكات العصبية المتكررة ذات الخلايا العصبية النشطة تتفوق في الأداء على نظيراتها التي تحتوي على خلايا عصبية عادية؛ كما أنها نظريًا أكثر كفاءة من الناحية الحسابية بواقع ثلاث مرات. يقول ساندر بوهتي، من معهد أمستردام القومي لبحوث الرياضيات وعلوم الكمبيوتر في هولندا (CWI)، الذي يعمل في هذا التخصص: "لا شك أن التقدم في هذا المجال يمضي بوتيرة سريعة ومثيرة للإعجاب".
وطالما استمرت عملية محاكاة هذه الشبكات العصبية النشطة فقط في البرمجيات الحاسوبية، فإنها لا تستطيع تحقيق مكاسب حقيقية في الكفاءة (نظرًا إلى أن الأجهزة التي تحاكيها لا تزال مستهلكة للطاقة). من ثمَّ، فهناك احتياج إلى دمج تلك العناصر الحوسبية في بنية الأجهزة على رقائق عصبية لأجل جني الفوائد المنتظرة منها.
نماذج لغوية كبيرة موفرة للطاقة
وفي الأثناء، يعكف الباحثون حاليًا على تجربة طرق مختلفة بإمكانها أن تجعل النماذج اللغوية الكبيرة القائمة أكثر كفاءة في استهلاك الطاقة، وأكثر ذكاءً. في ديسمبر 2021، أعلنت شركة «ديب مايند» عن نظام يُسمى «ريترو» RETRO، وهو نظام يجمع ما بين نموذج لغوي كبير وقاعدة بيانات خارجية. يستخدم ذلك النموذج نصوصًا ذات صلة مستدعاة من قاعدة البيانات المذكورة أثناء إجراء عملية الاستدلال لمساعدته على التنبؤ. أوضح باحثو «ديب مايند» أن الجمع ما بين نموذج لغوي كبير يحوي 7.5 مليار معامل، وقاعدة بيانات تضم تريليوني رمز مُشفَّر، يفوق في الأداء النماذج اللغوية الكبيرة التي تحوي معاملات أكثر بواقع 25 ضعفًا12. ذكر الباحثون أن ذلك النهج كان "أكثر كفاءة، مقارنةً بحجم المعاملات البحت، إذا كنا نسعى إلى بناء نماذج لغوية أقوى".
في الشهر ذاته، أعلن العلماء في «جوجل ريسيرش» عن طريقة أخرى لزيادة كفاءة استهلاك الطاقة بدرجة كبيرة. يحتوي النموذج الذي طوروه باسم «جلام» GLaM، وهو اختصار للنموذج اللغوي العام، على 1.2 تريليون معامل13. على أن هذه المعاملات لا تمثل شبكة عصبية عملاقة واحدة؛ وإنما تُوزِّع داخليًا بين 64 شبكة عصبية أصغر حجمًا، جنبًا إلى جنب مع طبقات أخرى. يُدرَّب النموذج اللغوي الكبير على أن يَستخدم أثناء عملية الاستدلال اثنتين فقط من شبكاته لإتمام مهمة بعينها. في العموم يستخدم النموذج حوالي 8% فقط من إجمالي معاملاته، التي يزيد عددها على تريليون معامل للاستدلال، لكل رمز مُشفَّر. أفادت شركة «جوجل» أن «جلام» قد استخدم نفس القدر من الموارد الحوسبية التي كانت لازمة لتدريب نموذج «جي بي تي-3»، إلا أن حجم الطاقة التي استهلكها لم يزِدْ عن الثلث؛ ومردُّ ذلك إلى التحسينات التي أدخلوها على البرامج التدريبية والأجهزة. استخدم «جلام» أثناء الاستدلال نصف الموارد الحوسبية التي احتاج إليها «جي بي تي-3»، كما أنه تفوق في الأداء على «جي بي تي-3» عندما دُرِّب على نفس كمية البيانات.
على الرغم من ذلك، فلكي يتمكن الباحثون من إجراء مزيد من التحسينات، يبدو أنه قد أصبح مقدَّرًا لهذه النماذج اللغوية الكبيرة الأكثر كفاءة في استهلاك الطاقة أن تكون أكبر حجمًا، وذلك مع استخدام المزيد من البيانات والعناصر الحوسبية. لن يغمض الباحثون أعينهم في معرض سعيهم لرصد السلوكيات الجديدة التي يمكن أن تنشأ بناء على زيادة حجم تلك النماذج. يقول بوبيك: "لست متأكدًا مما إذا كان ذلك سيفتح لنا كل الأبواب المغلقة لعملية الاستدلال المنطقي، وليس بإمكان أحد أن يعرف".
doi:10.1038/nmiddleeast.2023.131
1. Frieder, S. et al. Preprint at https://arxiv.org/abs/2301.13867 (2023).
2. Lewkowycz, A. et al. Preprint at https://arxiv.org/abs/2206.14858 (2022).
3. Chowdhery, A. et al. Preprint at https://arxiv.org/abs/2204.02311 (2022).
4. Kaplan, J. et al. Preprint at https://arxiv.org/abs/2001.08361 (2020).
5. Hoffmann, J. et al. Preprint at https://arxiv.org/abs/2203.15556 (2022).
6. Caballero, E. et al. Preprint at https://arxiv.org/abs/2210.14891 (2022).
7. Bubeck, S. et al. Preprint at https://arxiv.org/abs/2105.12806 (2021).
8. Le Scao, T. et al. Preprint at https://arxiv.org/abs/2211.05100 (2022).
9. Luccioni, A. S. & Hernandez-Garcia, A. Preprint at https://arxiv.org/abs/2302.08476 (2023).
10. Luccioni, A. S., Viguier, S. & Ligozat, A.-L. Preprint at https://arxiv.org/abs/2211.02001 (2022).
11. Yin, B. et al. Nature Mach. Intell. 3, 905–913 (2021).
12. Borgeaud, S. et al. Preprint at https://arxiv.org/abs/2112.04426 (2021).
13. Du, N. et al. Preprint at https://arxiv.org/abs/2112.06905 (2021).
29 April 2024
طريقة مصرية لتقليل تكلفة إنتاج خلايا البيروفسكايت الشمسية
29 April 2024
28 April 2024
اشترك للحصول على النشرة الإلكترونية المحدّثة كل أسبوعين لكي تبقى على اطلاع بكافة المستجدات على الموقع.
التسجيل في خدمة النشرات الإلكترونية (بالإنجليزية)
تواصل معنا: